http://www.sscnet.ucla.edu/polisci/faculty/groseclose/Media.Bias.8_files/image004.gif
[1] Our sample includes policy groups that are not usually called think tanks, such as the NAACP, NRA, and Sierra Club. To avoid using the more unwieldy phrase “think tanks and other policy groups” we often use a shorthand version, “think tanks.” When we use the latter phrase we mean to include the other groups, such as NAACP, etc.
[2] Eighty-nine percent of the Washington correspondents voted for Bill Clinton, and two percent voted for Ross Perot.
[3] “Finding Biases on the Bus,” John Tierney, New York Times, August, 1, 2004. The article noted that journalists outside Washington were not as liberal. Twenty-five percent of these journalists favored Bush over Kerry.
[4] “Ruling Class War,” New York Times, September 11, 2004.
[5] Cambridge and Berkeley’s preferences for Republican presidential candidates have remained fairly constant. In the House district that contains Cambridge, Bob Dole received 17 percent of the two-party vote in 1996, and George W. Bush received 19 percent in 2000. In the House district that contains Berkeley, Bob Dole received 14 percent of the two-party vote, and George W. Bush received 13 percent.
[6] Some scholars claim that news outlets cater not to the desires of consumers, but to the desires of advertisers. Consequently, since advertisers have preferences that are more pro-business or pro-free-market than the average consumer, these scholars predict that news outlets will slant their coverage to the right of consumers’ preferences. (E.g., see Parenti, 1986, or Herman and Chomsky, 1988.) While our work finds empirical problems with such predictions, Sutter (2002) notes several theoretical problems. Most important, although an advertiser has great incentive to pressure a news outlet to give favorable treatment to his own product or his own business, he has little incentive to pressure for favorable treatment of business in general. Although the total benefits of the latter type of pressure may be large, they are dispersed across a large number of businesses, and the advertiser himself would receive only a tiny fraction of the benefits.
[7] One of the most novel features of the Lott-Hasset paper is that to define unbiased, it constructs a baseline that can vary with exogenous factors. In contrast, some studies define unbiased simply as some sort of version of “presenting both sides of the story.” To see why the latter notion is inappropriate, suppose that a newspaper devoted just as many stories describing the economy under President Clinton as good as it did describing the economy as bad. By the latter notion this newspaper is unbiased. However, by Lott and Hasset’s notion the newspaper is unbiased only if the economy under Clinton was average. If instead it was better than average, Lott and Hasset (as many would recognize as appropriate, including us) would judge the newspaper to have a conservative bias. Like Lott and Hasset, our notion of bias also varies with exogenous factors. For instance, suppose after a series of events liberal (conservative) think tanks gain more respect and credibility (say, because they were better at predicting those events), which causes moderates in Congress to cite them more frequently. By our notion, for a news outlet to remain unbiased, it also must cite the liberal (conservative) think tanks more frequently. The only other paper of which we are aware that also constructs a baseline that controls for exogenous events is Tim Groeling and Samuel Kernell’s (1998) study of presidential approval. These researchers examine the extent to which media outlets report increases and decreases in the president’s approval, while controlling for the actual increases and decreases in approval (whether reported by the media or not). The focus of the paper, however, is on whether news outlets have a bias toward reporting good or bad news, not on any liberal or conservative bias.
[8] New York Times Executive Editor Howell Raines accepting the “George Beveridge Editor of the Year Award” at a National Press Foundation dinner, shown live on C-SPAN2 February 20, 2003.
[9] Paul Krugman, “Into the Wilderness,” New York Times, November 8, 2002.
[10] Al Franken (2003, 3) Lies and the Lying Liars Who Tell Them: A Fair and Balanced Look at the Right.
[11] Bill Moyers, quoted in “Bill Moyers Retiring from TV Journalism,” Frazier Moore, Associated Press Online, December 9, 2004.
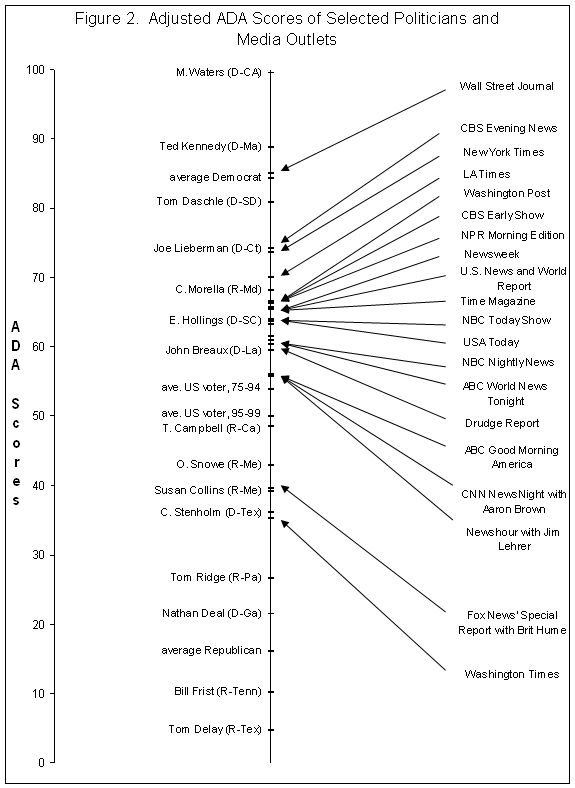
[12] Groseclose, Levitt, and Snyder (1999) argue that the underlying scales of interest group scores, such as those compiled by the Americans for Democratic Action, can shift and stretch across years or across chambers. This happens because the roll call votes that are used to construct the scores are not constant across time, nor across chambers. They construct an index that allows one to convert ADA scores to a common scale so that they can be compared across time and chambers. They call such scores adjusted ADA scores.
[13] Importantly, this conversion affects congressional scores the same way that it affects media scores. Since our method can only make relative assessments of the ideology of media outlets (e.g. how they compare to members of Congress or the average American voter), this transformation is benign. Just as the average temperature in Boston is colder than the average temperature in Philadelphia, regardless if one uses a Celsius scale or Fahrenheit scale, all conclusions we draw in this paper are unaffected by the choice to use the 1999 House scale or the 1980 House scale.
[14] In the Appendix we report the results when we do include citations that include an ideological label. When we include this data, this does not cause a substantial leftward or rightward movement in media scores—the average media score decreased by approximately 0.6 points, i.e. it makes the media appear slightly more conservative. Perhaps the greater affect was to cause a media outlets to appear more centrist. For instance, the New York Times and CBS Evening News tended to give ideological labels to conservative think tanks more often than they did to liberal think tanks. As a consequence, when we include the labeled observations, their scores respectively decreased (i.e. became more conservative) by 3.8 and 1.6 points. Meanwhile, Fox News’ Special Report tended to do the opposite. When we included labeled observations, its score increased (i.e., became more liberal) by 1.8 points. We think that such an asymmetric treatment of think tanks (ie to give labels more often to one side) is itself a form of media bias. This is why we base our main conclusions on the non-labeled data.
[15] Groseclose, Levitt, and Snyder (1999) have not computed adjusted scores for years after 1999. One consequence of this is that members who first entered Congress in 2001 do not have adjusted scores. ocrat. Third, even if the new members were not representative, this fact alone would not cause a bias in our method. To see this, suppose that these omitted members were disproportionately extreme liberals. To estimate ADA scores for a media outlet, we need estimates of the citation behavior of a range of members with ideologies near the ideology of the media outlet. If we had omitted some extreme liberal members of Congress, this does not bias our estimate of the citation pattern of the typical liberal, it only makes it less precise, since we have less data for these members. If, on the other hand, new members behaved differently from old members who have the same adjusted ADA score, then this could cause a bias. For instance, suppose new members with a 70 real ADA score tend to cite conservative think tanks more often than do old members with a 70 score. Then this would mean that Congress’s citation patterns are really more conservative than we have recorded. This means the media’s citation patterns are really more liberal (relative to Congress) than they appear in our data set, which would mean that the media is really more liberal than our estimates indicate. However, we have no evidence to believe this (or the opposite) is the case. And even if it were, because the new members are such a small portion of the sample, any bias should be small.
[16] In fact, for all members of Congress who switched parties, we treated them as if they were two members, one for when they were a Democrat and one for when they were a Republican.
[17] The party averages reflect the midpoint of the House and Senate averages. Thus, they give equal weight to each chamber, not to each legislator, since there are more House members than senators.
[18] Table 3, in the “Estimation Results” section, lists the period of observation for each media outlet.
[19] We assert that this statement is more likely to be made by a conservative because it suggests that government spending is filled with wasteful projects. This, conservatives often argue, is a reason that government should lower taxes.
[20] We were directed to this passage by Sutter’s (2001) article, which also seems to adopt the same definition of bias that we adopt.
[21] Like us, Mullainathan and Shleifer (2003) define bias as an instance where a journalist fails to report a relevant fact, rather than chooses to report a false fact. However, unlike us, Mullainathan and Shleifer define bias as a question of accuracy, not a taste or preference. More specific, their model assumes that with any potential news story, there are a finite number of facts that apply to the story. By their definition, a journalist is unbiased only if he or she reports all these facts. (However, given that there may be an unwieldy number of facts that the journalist could mention, it also seems consistent with the spirit of their definition that if the journalist merely selects facts randomly from this set or if he or she chooses a representative sample, then this would also qualify as unbiased.) As an example, suppose that, out of the entire universe of facts about free trade, most of the facts imply that free trade is good. However, suppose that liberals and moderates in Congress are convinced that it is bad, and hence in their speeches they state more facts about its problems. Under Mullainathan and Shleifer’s definition, to be unbiased a journalist must state more facts about the advantages of free trade—whereas, under our definition a journalist must state more facts about the disadvantages of free trade. Again, we emphasize that our differences on this point are ones of semantics. Each notion of bias is meaningful and relevant. And if a reader insists that “bias” should refer to one notion instead of the other, we suggest that he or she substitute a different word for the other notion, such as “slant.” Further, we suggest that Mullainathan and Shleifer’s notion is an ideal that a journalist perhaps should pursue before our notion. Nevertheless, we suggest a weakness of Mullainathan and Shleifer’s notion: It is very inconvenient for empirical work, and perhaps completely infeasible. Namely, it would be nearly impossible—and at best a very subjective exercise—for a researcher to try to determine all the facts that are relevant for a given news story. Likewise, it would be very difficult, and maybe impossible, for a journalist to determine this set of facts. To see this, consider just a portion of the facts that may be relevant to a news story, the citations from experts. There are hundreds, and maybe thousands, of think tanks, not to mention hundreds of academic departments. At what point does the journalist decide that a think tank or academic department is so obscure that it does not need to be contacted for a citation? Further, most think tanks and academic departments house dozens of members. This means that an unbiased journalist would have to speak to a huge number of potential experts. Moreover, even if the journalist could contact all of these experts, a further problem is how long to talk to them. At what point does the journalist stop gathering information from one particular expert before he or she is considered unbiased? Even if a journalist only needs to contact a representative sample of these experts, a problem still exists over defining the relevant universe of experts. Again, when is an expert so obscure that he or she should not be included in the universe? A similar problem involves the journalist’s choice of stories to pursue. A news outlet can choose from a huge—and possibly infinite—number of news stories. Although Mullainathan and Shleifer’s model focuses only on the bias for a given story, a relevant source of bias is the journalist’s choice of stories to cover. It would be very difficult for a researcher to construct a universe of stories from which journalists choose to cover. For instance, within this universe, what proportion should involve the problems of dual-career parents? What proportion should involve corporate fraud?
[22] Originally we used Stata to try to compute estimates. With this statistical package we estimate that it would have taken eight weeks for our computer to converge and produce estimates.
[23] However, Hamilton also notes that CBS covered roll calls by the American Conservative Union more frequently than the other two networks. Nevertheless, one can compute differences in frequencies between roll calls from the ADA and ACU. These differences show CBS to be more liberal than ABC and NBC. That is, although all three networks covered ADA roll calls more frequently than they covered ACU roll calls, CBS did this to a greater extent than the other two networks did.
[24] Other anecdotes that Sperry documents are: (i) a reporter, Kent MacDougall, who, after leaving the Journal, bragged that he used the “bourgeois press” to help “popularize radical ideas with lengthy sympathetic profiles of Marxist economists”; (ii) another Journal reporter who, after calling the Houston-based MMAR Group shady and reckless, caused the Journal to lose a libel suit after jurors learned that she misquoted several of her sources; (iii) a third Journal reporter, Susan Faludi (the famous feminist) characterized Safeway as practicing “robber baron” style management practices.
[25] See
http://people-press.org/reports/display.php3?ReportID=215 for a description of the survey and its data. See also Kurtz (2004) for a summary of the study.
[26] This comes from the estimates for the “Republican” coefficient that they list in their Table 7. These estimates indicate the extent to which a newspaper is more likely to use a negative headline for economic news when the president is Republican. .
[27] Sometimes even liberals consider NPR left-wing. As Bob Woodward notes in The Agenda (1994, p. 114). “[Paul] Begala was steaming. To him, [OMB Director, Alice] Rivlin symbolized all that was wrong with Clinton’s new team of Washington hands, and represented the Volvo-driving, National Public Radio-listening, wine-drinking liberalism that he felt had crippled the Democratic Party for decades.”
[28] To test that NPR is to the right of Joe Lieberman we assume that we have measured the ideological position of Lieberman without error. Using the values in Table 2 and 3, the t-test for this hypothesis is t = (74.2 – 66.3)/1.0 = 7.9. This is significant at greater than 99.9% levels of confidence. To test that NPR is to the right of the New York Times, we use a likelihood ratio test. The value of the log likelihood function when NPR and the NY Times are constrained to have the same score is -78,616.64. The unconstrained value of the log likelihood function is -78,609.35. The relevant value of the likelihood ratio test is 2(78,616.64-78,609.35). This is distributed according to the Chi-Square distribution with one degree of freedom. At confidence levels greater than 99.9% we can reject the hypothesis that the two outlets have the same score.
[29] Of the reports written by Matt Drudge, he cited the Brookings Institution twice (actually once, but he listed the article for two days in row) the ACLU once, Taxpayers for Common Sense once, and Amnesty International once. On June 22, 2004, the Drudge Report listed a link to an earlier version of our paper. Although that version mentioned many think tanks, only one case would count as a citation. This is the paraphrased quote from RAND members, stating that the media tends to cite its military studies less than its domestic studies. (The above quote from PERC was not in the earlier version, although it would also count as a citation.) At any rate, we instructed our research assistants not to search our own paper for citations.
[30] Nevertheless, we still report how our results change if instead we use median statistics. See footnotes 34 and 35.
[31] The year 1999 was somewhat, but not very, atypical. During the rest of the 1990s on average 17.6 senators received scores between 33 and 67, approximately half as many as would be expected if scores were distributed uniformly. See
http://www.adaction.org/votingrecords.htm for ADA scores of senators and House members.

")